When Anthropic launched Claude Opus 4.7 on April 16, 2026 alongside updates to its agentic command-line tool, Claude Code, it became the company's most capable publicly available model, posting record coding benchmarks. However, the developer community immediately began analyzing its actual performance, a silent tokenizer cost change, and new API breaking changes. Here is the comprehensive, honest review of the launch.
While the coding capabilities are undisputed, the community's reaction highlights a major shift in how developers budget their token usage. Opus 4.7 ships with an updated tokenizer that can quietly raise real costs even though the rate card is unchanged. We pulled together the official benchmarks, the system card, the community reports, and competitor comparisons to give you the honest read.
By the end of this review, you will understand exactly how Claude Opus 4.7 performs in production and how to manage its effort levels and costs without surprises on your bill.
What Anthropic Actually Shipped
The release of Claude Opus 4.7 introduced several critical features for developers:
Feature | What Changed |
|---|---|
Effort Levels & Task Budgets | Five reasoning effort levels — low, medium, high, the new xhigh, and max — plus task budgets (beta) for finer control over depth versus latency. |
Claude Code + /ultrareview | The terminal agent that runs tests, edits files, uses git, and executes commands autonomously gained a new |
SWE-bench Verified SOTA | Scored 87.6% on software engineering tasks, up from 80.8% on Opus 4.6 and leading rival frontier models. |
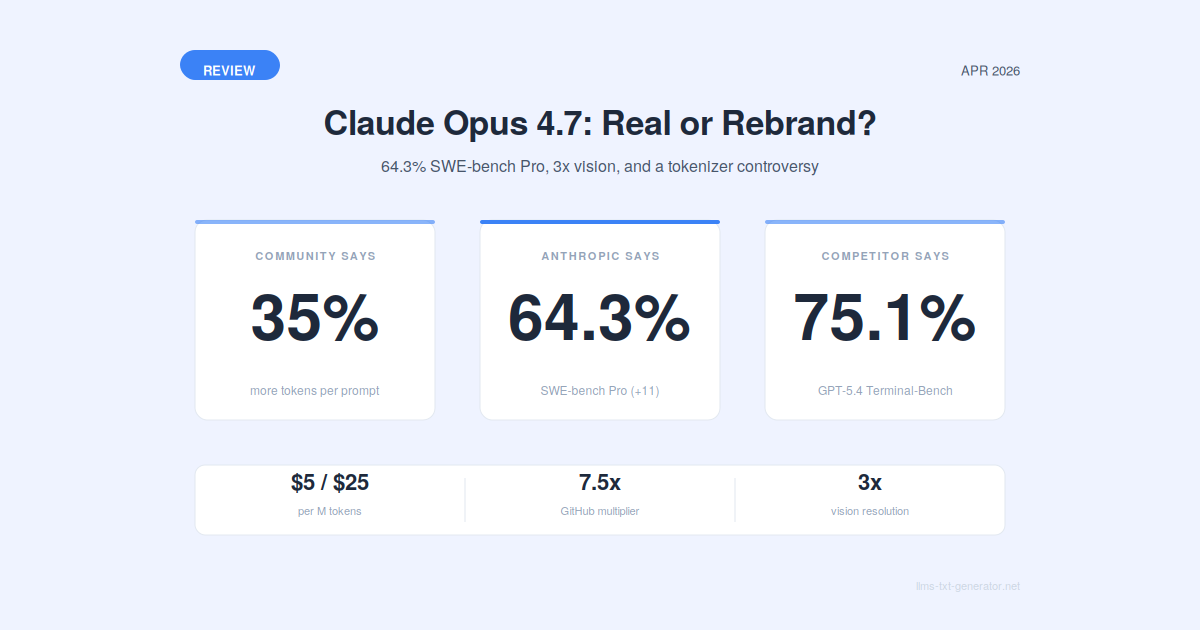
Pricing | $5.00 / $25.00 per million tokens — identical to Opus 4.6, but an updated tokenizer can map the same text to more tokens. |
Model ID |
|
What the Benchmarks Show
Anthropic's system card demonstrates a focused upgrade over Opus 4.6, with the biggest gains in real-world software engineering:
Benchmark | Claude Opus 4.6 | Claude Opus 4.7 | Change |
|---|---|---|---|
SWE-bench Verified | 80.8% | 87.6% | +6.8 |
SWE-bench Pro | 53.4% | 64.3% | +10.9 |
GPQA Diamond | 91.3% | 94.2% | +2.9 |
The coding gains are substantial. Scoring 87.6% on SWE-bench Verified — and a 10.9-point jump on the harder SWE-bench Pro — means the model can autonomously locate, edit, and verify code changes across multi-file repositories with high reliability. Anthropic also reports a 14% improvement on complex multi-step workflows versus Opus 4.6 while producing roughly a third of the tool errors.
The Tokenizer Cost Controversy
Although Anthropic kept the baseline pricing at $5/$25 per million tokens, the community quickly realized that **the updated tokenizer can significantly increase the real cost per query**. The same input text can map to roughly 1.0–1.35x more tokens than Opus 4.6 — meaning your bill per request can climb up to 35% even though the rate card never changed.
Anthropic recommends measuring the difference on real traffic. For teams running agentic tools like Claude Code at scale, this "silent" change is the single most important thing to budget for, and it has driven community guides on re-measuring token spend after upgrading. (Note: GitHub Copilot rolled out Opus 4.7 with a temporary 7.5x premium multiplier during its promotional window.)
Stricter Instruction-Following & Breaking Changes
Another area of discussion in developer forums is that Opus 4.7 follows instructions more literally than its predecessors. Prompts that relied on the model "filling in the gaps" may need adjusting, and Anthropic shipped three hard API breaking changes alongside the silent tokenizer shift — so teams should read the release notes before upgrading. On the upside, Opus 4.7 is the first Claude model to pass Anthropic's "implicit-need tests," inferring required tools rather than being told explicitly, and it adds multi-agent coordination for parallel workstreams.
Which Effort Level Should You Use?
High / xhigh / max, for: Complex multi-file refactoring, debugging logical errors, writing algorithms, and solving advanced math/logic proofs.
Low / medium, for: Simple text formatting, writing standard boilerplate, generating basic CSS/HTML layouts, or running repetitive API pipelines.
How This Connects to Your Website
As developers adopt Claude Code and Claude Opus 4.7 to automate coding tasks, these agents browse documentation, tutorials, and libraries online to fetch references.
If these agents crawl your website to retrieve information on behalf of a developer, they consume tokens. A clean, structured llms.txt file at your domain root serves as a direct roadmap for these models, preventing them from wasting their reasoning budgets parsing redundant HTML menus and layouts.
Generate your free llms.txt file in 60 seconds and optimize your documentation for agentic AI crawlers.
Conclusion
Claude Opus 4.7 is a powerful reasoning model that sets new standards for AI-assisted software engineering. While its benchmark gains are real and substantial, the updated tokenizer and API breaking changes mean developers must re-measure costs and adjust prompts after upgrading. By choosing appropriate effort levels and budgeting tokens carefully, you can leverage its full power efficiently.
As AI agents increasingly dominate web traffic, the best way to ensure your site is read and cited accurately is to provide a clean, machine-readable llms.txt. Generate your free llms.txt file today →
Frequently Asked Questions
What is Claude Opus 4.7?
Claude Opus 4.7 is Anthropic's most capable publicly available model, released in April 2026 with state-of-the-art performance in coding, reasoning, and agentic tasks. It offers developer-controlled effort levels (low, medium, high, xhigh, and max) and a 1M-token context window.
How does the new tokenizer affect cost?
Opus 4.7's updated tokenizer can map the same text to roughly 1.0–1.35x more tokens than Opus 4.6, so real cost per request can rise up to about 35% even though the $5/$25 per-million-token rate is unchanged. Anthropic recommends measuring the difference on your own traffic.
What is Claude Code?
Claude Code is a terminal-based agentic CLI tool developed by Anthropic. It allows Claude to interact directly with your local files, execute terminal commands, run tests, and manage git commits autonomously, and Opus 4.7 added a new /ultrareview command.
How do I control reasoning depth?
In the Anthropic API, you can set the effort level — low, medium, high, xhigh, or max — and use task budgets (beta) to scale how much the model reasons for a given request, or keep it low for simple queries.